
Assignment1.3: KNN
这个实验之前做过,说白了就是求距离:
- 用两个for循环
- 用一个for循环
- 完全不用for循环
然后还有几个numpy函数的用法:
- np.bincount
- np.array_split
- 等等
这些用处都不是很大。
这里把代码贴上:
1 | ## Two for loops: |
完事,下班!
这个实验之前做过,说白了就是求距离:
然后还有几个numpy函数的用法:
这些用处都不是很大。
这里把代码贴上:
1 | ## Two for loops: |
完事,下班!
SVM数学原理还挺复杂的,涉及到什么拉格朗日乘子法,还是不等式约束,这里挖一个坑,之后尽量补充进来。

代码:
1 |
|
这里最后的减去1,意思就是sigma求和下面那个$y_i\neq j$,对于true label,我们并不计算loss
1 |
|
这里这个-1,意思也是我们对true label并不处理
计算 row_sum的意思就是计算有多少 大于零的,大于零的根据求导公式要减去。
这个主要是数学求导…
这里基本上和之前neural network中第一步完全一样,但仍然有一些需要注意的:
再放一遍代码:
1 | N = X.shape[0] |
这里又学到一个minibatch的选择方法:
1 | # version 1 |
其他就都比较正常了,下班!
1 | inner1_act = np.maximum(zeros, inner1) |
注意这里使用maximum,而不是max,max会出大问题
首先,需要把每个sample减去最大值,防止上溢下溢。
首先softmax公式如下:
$$
softmax(x)_i = \frac{e{x_i}}{\sum_{j}{e{x_j}}}
$$
这里我们减去最大值,即为了防止上溢和下溢
举个例子,x=[100000,100001,100002],如果直接代入上式数值会非常大,当对每个x的值减去x中的最大值后得到[-2,-1,0],此时再代入上式。
我试过加这个步骤,和不加,结果是一模一样的,应该可以证明这样对结果不产生影响,只是简化了计算。
之后,就是numpy的究级切片:
1 | probs[range(N), y] |
probs是一个(5,3)维的矩阵,有5个sample,3个维度,y是类似[0,1,1,2,0]的真实标签。
因为cross entropy公式:
$$
Loss = -\sum_{i=1}^{m}{y_ilog(a_i)}
$$
$y_i$ 是one-hot 标签,所以在其他维度都为零,有一个选择的过程,上面这行代码就做出了这个选择。只选y对应的那一列。
经典的$a-1$倒数,具体可以参考:
这里就需要稍微细心一点,每一步对应的维度要算对。
1 | mini_batch = np.random.permutation(num_train)[0:batch_size] |
挺好用的一个打乱方法。
参数更新也很直接:
1 | self.params['W1'] -= learning_rate * grads['W1'] |
本次实验到此结束。
表达欲异常膨胀,既然今天是妇女节,就从这个说起吧。
既然是周记,也没人看,那就直抒胸臆。
非常讨厌一种人,就是人云亦云,没有丝毫主见。
女神节的时候跳的特别欢,现在妇女节又跟着潮流大肆表达妇女所谓独立的精神。
观点也许不错,但是这种跟风起哄,真的很讨厌。
国足输球了,会出来骂一句,然而只知道骂,不知道该骂谁,骂得也没有丝毫逻辑。
女足赢球了,就是women是冠军,疯狂到爆炸,与有荣焉,然后奥运会被灌了八个球没见这些人有多可惜,那个时候他们在哪里呢?
天天男性凝视挂在嘴边,喊着平等的口号,然而和男生一起出去吃着免费的晚餐,看着免费的电影,这个时候凝视在哪里?独立在哪里?平等在哪里?
不吐不快,以上。
/etc/resolv.conf
加入
nameserver 8.8.8.8
在/.bashrc或者/.zshrc等终端配置文件中加入如下行,并对底部所述的相应变量进行替换:
1 | alias weblogin="curl \"http://202.113.18.106:801/eportal/?c=ACSetting&a=Login&loginMethod=1&protocol=http%3A&hostname=202.113.18.106&port=&iTermType=1&wlanuserip=IP_ADDR&wlanacip=null&wlanacname=jn1_&redirect=null&session=null&vlanid=0&mac=00-00-00-00-00-00&ip=IP_ADDR&enAdvert=0&jsVersion=2.4.3&DDDDD=USER_ID&upass=USER_PWD&R1=0&R2=0&R3=0&R6=0¶=00&0MKKey=123456&buttonClicked=&redirect_url=&err_flag=&username=&password=&user=&cmd=&Login=\"" |
保存并退出后 source ~/.bashrc 或者 source ~/.zshrc 。
再输入 weblogin即可登陆成功,相应地输入weblogout即可登出。
1 | unzip data.zip -d ./data/ |
unzip不会保留原文件夹,所以一般需要-d参数
直接
1 | pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple |
就行了
包菜去外皮,撕成小块
干辣椒
这个挺简单的,就是用一个数组记录所有内容,然后随机就完事了:
1 |
|
但这并不是我们想要的,这道题原始是希望不知道数据总体有多大时,也能做到随机取样(不能加载所有数据时)
即:当内存无法加载全部数据时,如何从包含未知大小的数据流中随机选取k个数据,并且要保证每个数据被抽取到的概率相等。
当 k = 1 时,即此题的情况
也就是说,我们每次只能读一个数据。
假设数据流含有N个数,我们知道如果要保证所有的数被抽到的概率相等,那么每个数抽到的概率应该为 1/N
那如何保证呢?
先说方案:
每次只保留一个数,当遇到第 i 个数时,以 1/i的概率保留它,(i-1)/i的概率保留原来的数。
举例说明: 1 - 10
遇到1,概率为1,保留第一个数。
遇到2,概率为1/2,这个时候,1和2各1/2的概率被保留
遇到3,3被保留的概率为1/3,(之前剩下的数假设1被保留),2/3的概率 1 被保留,(此时1被保留的总概率为 2/3 * 1/2 = 1/3)
遇到4,4被保留的概率为1/4,(之前剩下的数假设1被保留),3/4的概率 1 被保留,(此时1被保留的总概率为 3/4 * 2/3 * 1/2 = 1/4)
以此类推,每个数被保留的概率都是1/N。
代码为:
1 | class Solution { |
这里就是个dp或者用矩阵快速幂
dp
1 | class Solution { |
快速幂
待查,以后再补这一点吧
先排序,然后转换为分钟,再遍历:
1 | class Solution { |
hashmap 的巧妙利用
1 | class Solution { |

这题并不知道怎么做,抄的,待查
1 | class Solution { |
这题也待查吧,先放在这里:
1 | class Solution { |
这个太简单了,就判断一下是不是回文,如果是,一步就够了,如果不是,也就两步。
1 | class Solution { |
头一回坐飞机,总结下流程嘻嘻

白话就是选座,我是在同程上订的,大概会提前20-30小时可以提前在线值机,但是基本上好位置全没有了。
托运行李,之前在网上查了很多关于托运的注意事项,70%以上的酒精等等,但是真正托运的时候,似乎什么也没检查,直接贴上凭条就传送走了。
安检需要把随身物品和电子物品取出来,同时液体只能带小于100ml的容器。
一个靠窗远离机翼的位置还是很重要的,飞行大概分这么几个阶段:
厦门航空的晚餐比较坑,就给了一个点心,一个小汉堡,一根香蕉,一杯水,体验较差
提前在爱彼迎定的民宿,非常靠近地铁站,去哪里都很方便,每晚¥155.6,三个人,还算比较实惠
早餐在小南门,之前查攻略说这里是当地人吃早餐的地方,实际上确实是,但是本地人吃的是真的不太合我们的口味……豆腐脑的汤汁非常非常的稀,而且非常的酸,非常吃不过,豆浆和油条都很好

去的时候可能还是太早了,店铺都在准备,不过没有发现什么好东西,无非是笔墨纸砚这些,还有些兵马俑一类的古董玩器,和天津的鼓楼差不太多。
来之前心心念念的地方,写了那么久的玄秘塔碑,终于有机会看到真碑,也看到了当场拓片的过程,感觉还是挺值得的


下面就是玄秘塔碑,柳体的筋骨真的,远超其他楷体


!
寻找午餐的过程,发现了“传说中”的青曲社,如下图

门可罗雀,一个人都没,真好。
午餐在 秦豫肉夹馍 吃的,这里人真的不是一般的多,有种回到了食堂的感觉,吃到嘴里其实感觉还挺一般,只有馍和瘦肉,肥肉很少,我印象中的肉夹馍是肥瘦相间,然后加一些青红椒,油汁很多,饼非常酥脆,非常非常好吃的,哈哈可能我吃到的是天津人魔改版本吧,就想吃惯了加生菜鸡排的煎饼再到天津也会不适应。

这个景点,说实话吧,其实120的门票有些不值,一些山山水水的景观造的的确不错,但是没看出来有什么唐代的特点,也没看到有什么特别的演出,总体上挺失望的

不夜城真的好大,而且管理井井有条,真的非常不容易,里面的吃的价格也算合理,晚上遛弯确实不错,里面有几个雕塑真的很大很壮观。
这个景点可以排在西安游的前三,太震撼了,仔细想想,推出这个喷泉要用到,时控喷泉(精准到秒)、音乐(激昂、平缓皆备)、城市园林管理(场地安排)、景点编排(演出时间点),各方努力展现出现在这个样子,确实非常非常非常厉害了。
全称 Differentiable ARchiTecture Search
它是一种新(2018)的NAS(神经架构搜索)方法。
全称: neural architecture search(神经架构搜索)
简单讲就是把设计神经网络的任务也交给机器。
企图把人工炼丹的过程一步步转化为机器炼丹。
具体说可以看看wiki上的定义:

也就是一般的NAS都会包含三个部分:
它们之间的关系可以大概用下面这个图表示
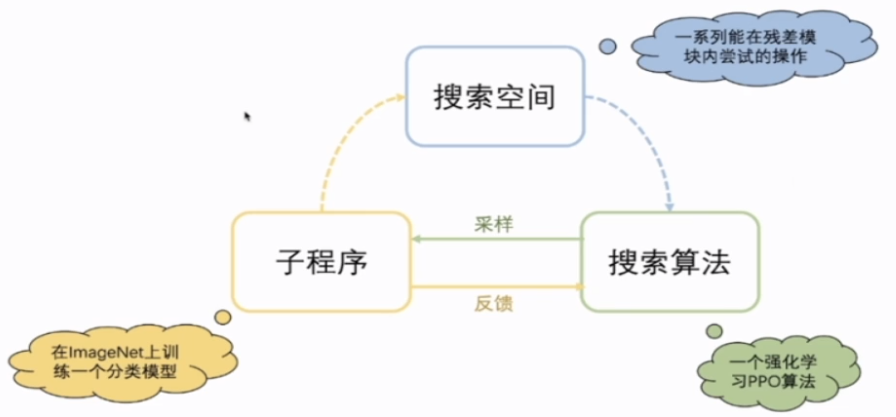
图源:VALSE_Webinar 20201223 Xuanyi Dong 侵删
NAS的一般流程也可以总结为:
上面的NAS流程问题在哪里?
问题在于每次找到一个新的模型,判断这个模型好坏是个麻烦事。
要是每个模型都train一遍吧,实在是太慢了(2000 gpu days),可要是不train吧,那怎么判断搜到的模型是好是坏?
这时,darts就出现了,既然train太慢了,那就少 train 一点吧!

图源 成都卫视 谭谈交通 侵删
但是少train也不是简简单单减少数据集这么简单,得有一个足够好的优化算法,保证我每次虽然 train 的少,还能为下次迭代找到正确的方向。
一起来看看darts是怎么做的吧!
首先熟悉一下darts中的名词:
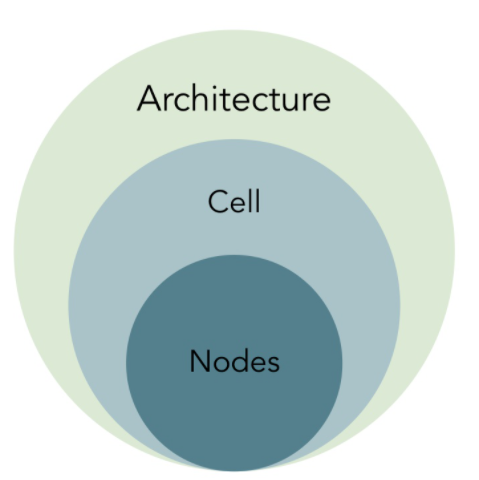
图源 知乎 @Kadima 侵删
首先,darts最后要得到的就是一个 Architecture,神经网络的总结结构,然后,darts内部预先定义好了8个cell,每个cell里面有4个node,每个node就是一个latent representation。(这些都是定好的,不能搜出来哦)
要搜索的就是,node之间如何连接,也就是节点之间的边:
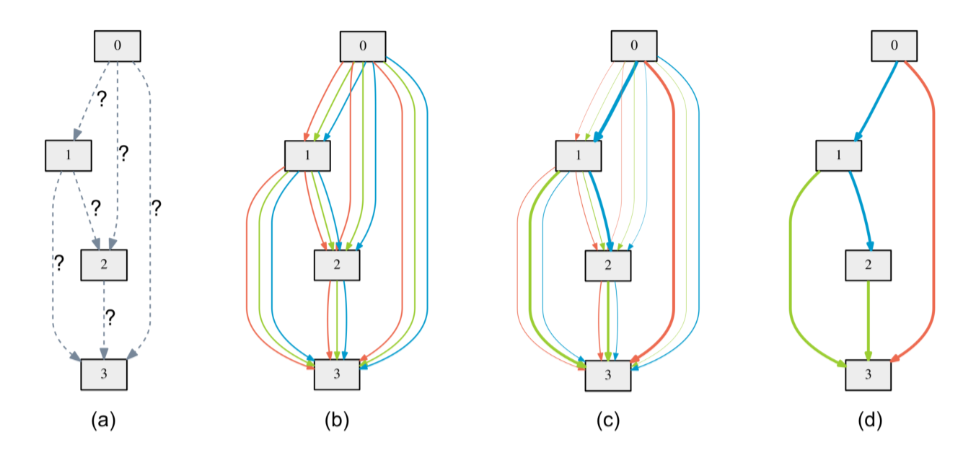
图源 darts论文 不删
是时候祭出原文中的这张图了。
可以看到,每个节点的输入,都是其所有前驱节点的输出,也就是说,如果是第二个node,那输入就是第一个node的输出。如果是第四个node,那输入就是前三个的输出。值得注意的是:
那这些可选的边,都包括哪些呢?
从代码可以看出来,可选的并不多:
1 | PRIMITIVES = [ |
所以我们现在知道了,darts大概就是
选合适的边,给node连上。
idea挺直接的,那怎么做呢?
这一步解决的就是,用softmax,让不同 边 共存,供算法后续的优化、选择。
具体来讲,就是原文中的这个公式:
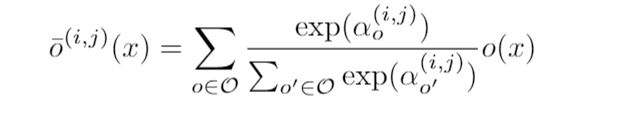
大 O 就是刚才我们看到,代码里的八个操作,小o就是每个操作,α是每个操作的权重,最后 α杠 就是融合后的operation。
现在问题来了,阿尔法(α)是个新的参数,每个不同的阿尔法(α)对应一个特殊的网络结构,也就意味着,每个阿尔法(α)都自己对应一组最优的网络参数 $w$,怎么优化这个问题呢?
论文对上述问题的描述,比我说的清晰:

首先,我们最终的目标函数,是优化公式3,也就是找到 loss 最小的那个阿尔法(α),但是得在w是最优时,才能比较不同阿尔法(α)的 loss,所以要满足公式2。
也就是要使得,这个$w$ 是当前阿尔法(α)的最优解。
当然,这是理想情况,现实找到这样的最优解太困难了,来看看 darts 是怎么做的:

第一步中有个小括号,熟悉的同学可能一眼就看出是个梯度下降的公式。
也就是说,不仅在第二步更新w,在第一步也更新一下。
这也就是论文中说的second order approximation,对应的 first order approximation 就没有这个小括号里得内容了。
看完了对问题的形式化描述,也看完了darts提出的近似算法,很自然的想法是,这能work???
然而残酷的是,真的work
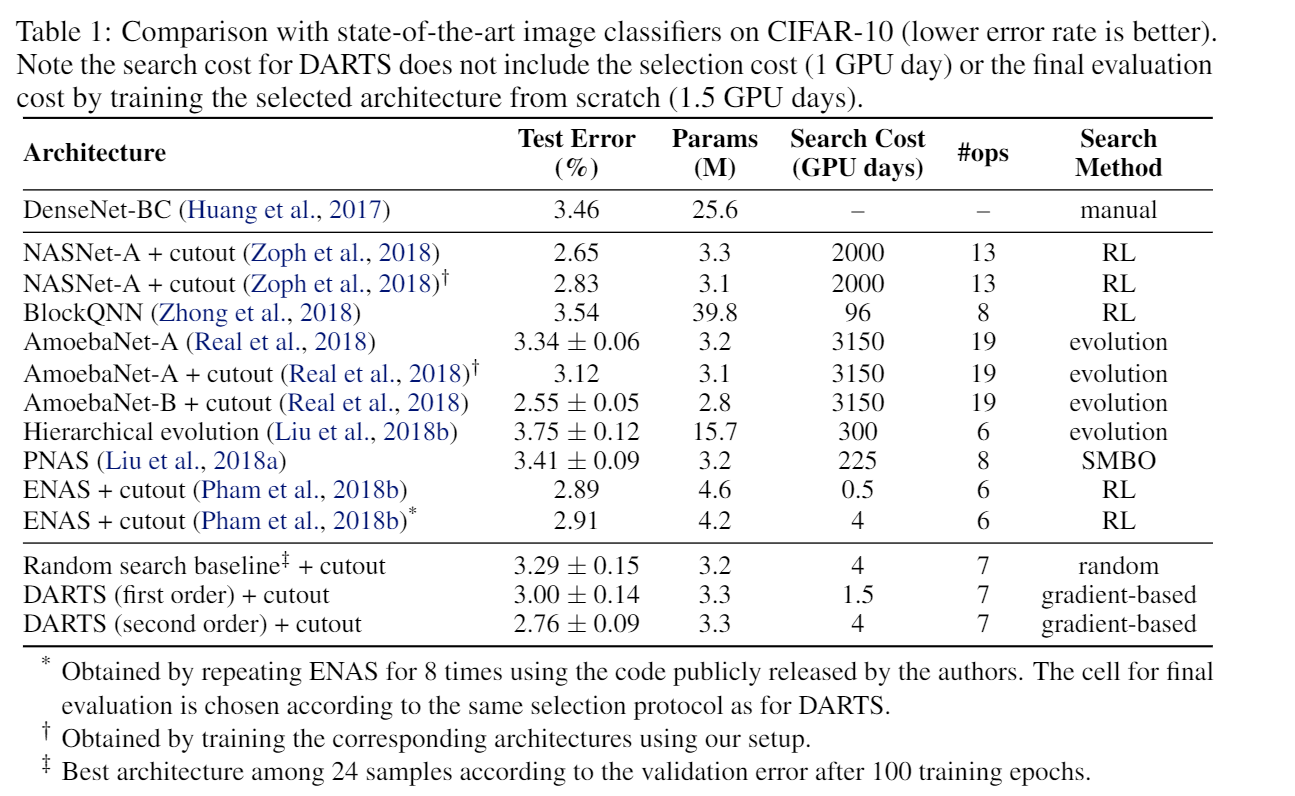
这结果还好滴很呢。
当然优秀的论文总不会满足于实验结果很好,文章里提出了两个很重要的问题,并作出了回答:
问题一,答案是不确定。找好学习率,实践上是可以的,理论上还不好说。
原文解释:

问题二:不是全局最优:
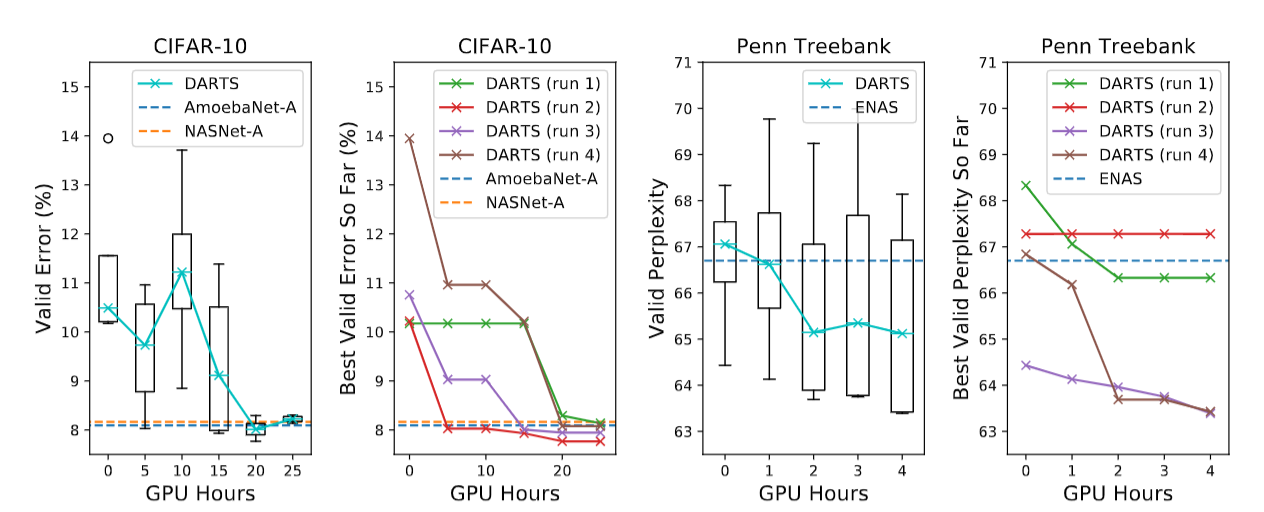
对于CNN,好像最后结果差不多,但是对于RNN,可以看到不同的初始化,结果能差四个点左右,足以证明得到的解并不是全局最优。
文章看完以后问题挺多,总结如下
第一:算法第一步为什么外层用val,里层用train?

第二:为什么这样做结果还不错呢?
如果我在第一步做两层优化呢?或者两步改成三步,第一步是优化w,第二步是优化阿尔法(α),第三步再优化w,这和原作一样吗?
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true